Les graphiques en barres empilées sont notoirement peu lisibles, la presse le sait et les évite. Des alternatives plus efficaces existent. Nous les rencontrons pourtant partout dans la production institutionnelle : pas une étude statistique, pas un rapport d’activité où l’on ne subisse ces guirlandes de bâtons multicolores[1], leurs légendes extensibles et leurs inévitables aides au déchiffrage.
Prenons deux exemples publiés la semaine dernière : à chaque fois la matière est intéressante, mais le traitement graphique la dessert.
Vous avez 5 secondes pour capter une première idée simple qui vous surprenne et vous donne envie d’aller plus loin dans l’exploration (j’aime bien ce test basique, que m’a confié un data-journaliste).
Publication de la Drees : Impact des assurances complémentaires santé et des aides sociofiscales à leur souscription sur les inégalités de niveau de vie (septembre 2022)
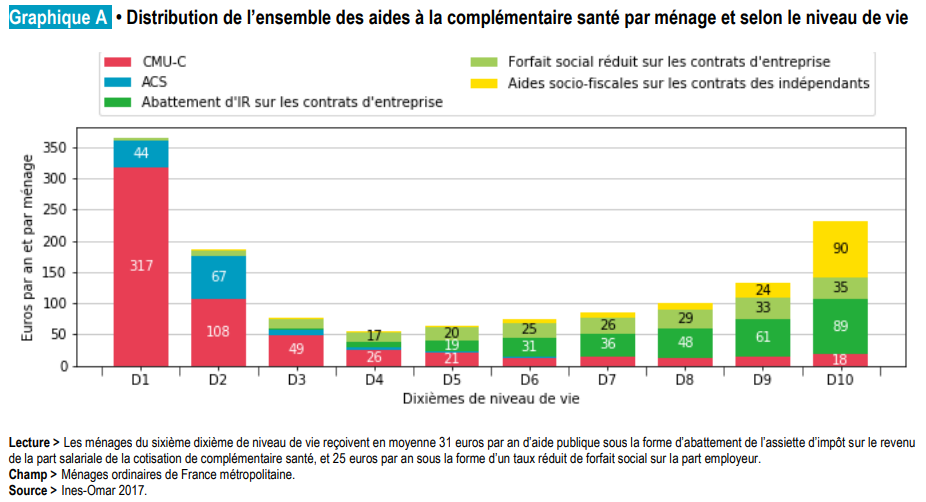
Vous n’y êtes pas arrivés ? Ou vous avez seulement vu dans le 1er exemple que la CMU concerne surtout les plus précaires, ce qui ne vous a rien appris ? Ne stressez pas, c’est normal. Ces graphiques n’offrent pas de point d’entrée évident, et l’absence de titre informatif ne fait rien pour les sauver. Faute de base horizontale ou verticale commune, la plupart des séries (identifiées par une même couleur) ne sont pas signifiantes « dans l’instant minimal de vision », pour reprendre les mots de Jacques Bertin, le grand sémiologue français.
Considérez par exemple la série rose pâle ci-dessus : présente-t-elle ou non des variations significatives ? Cela ne saute pas aux yeux. Seules les séries jaunes et violettes, aux extrémités, sont rapidement évaluables, disposant d’un solide point d’appui à gauche ou à droite.
Souvent, la juxtaposition de couleurs vives complique l’effort de sélection que l’œil doit conduire pour isoler chaque concept. On le constate dans le premier graphique, par ailleurs constellé de chiffres sans grand intérêt. Enfin, qui souffre de déficience visuelle, même légère, sera peu à la fête, compte tenu du nombre de couleurs à distinguer ou de l’emploi abusif de l’opposition rouge / vert.
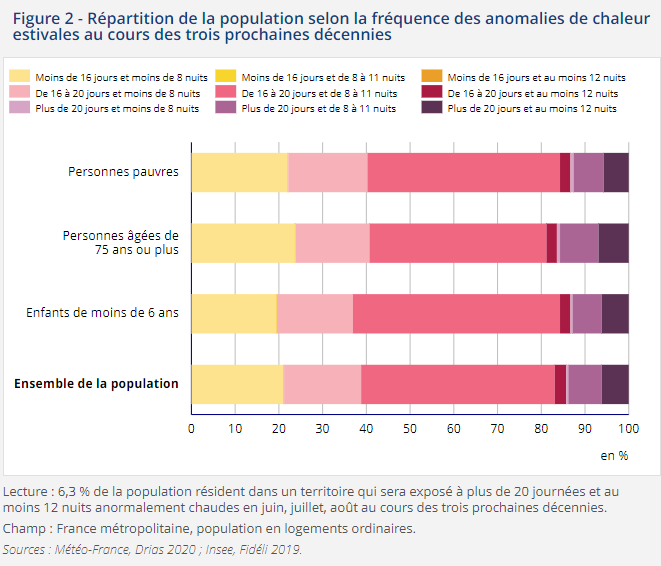
Le second graphique (Insee) est un peu plus amical : moins de chiffres, des couleurs plus douces, des axes plus explicites. Mais je n’en retiens rien – si je refuse d’y passer plus de 20 secondes – trop de catégories sans contraste évident surchargent ma mémoire de travail.
Désempilez et simplifiez en catégorisant
Revenons aux données publiées par la Drees. Comment leur rendre mieux justice ?
Il s’agit de dépenses de santé et des différentes aides soutenant les ménages selon leur niveau de vie : cela concerne et parle – a priori – à tout le monde. Quels sont les principaux contrastes, les lois et les ordres de grandeur à retenir ?
La science de la sémiologie graphique, formalisée par Jacques Bertin et Edward Tufte, pour ne citer que les plus connus, nous donne les règles à suivre, dont voici une mise en musique.
Les variables visuelles les plus efficaces sont la position dans le plan et la longueur rapportée à une base commune. L’organisation du diagramme suivant, en colonnes, et ses barres horizontales alignées à gauche répondent à ces critères.
La loi de proximité issue de la théorie de la Gestalt[2] privilégie le légendage direct de chaque série. Il est naturellement assuré par la disposition tabulaire : plus besoin d’une légende déportée obligeant à des allers et retours visuels fastidieux.
La théorie de la charge cognitive (que Bertin anticipe) encourage les tris logiques et l’extraction de grandes catégories : on oppose ici de gauche à droite les aides ciblant les niveaux de vie modestes à celles concernant les plus aisés. À côté de ces deux grandes catégories, qui dégagent une première image mentale facile à imprimer, le profil du total des aides relève d’un autre niveau de lecture : la distribution est symétrique, elle favorise les extrémités de l’éventail des niveaux de vie.
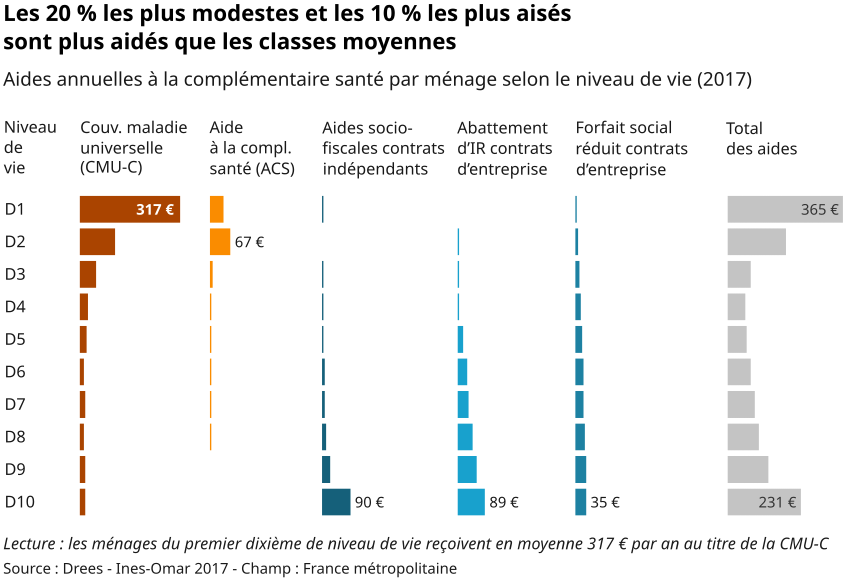
L’emploi de la couleur, subtil et souriant, souligne ces différents niveaux de lecture. Il laisse de côté le funeste duo rouge-vert rétif aux daltoniens, et n’hésite pas à utiliser le gris.
Quelques chiffres clés sont portés pour saisir l’ordre de grandeur des barres et souligner les maxima ainsi que les oppositions entre les deux principaux groupes d’aides. L’unité € précise ces chiffres pour une appréhension immédiate de ce dont il s’agit (un montant financier).
Avec ces chiffres repères, nul besoin de dessiner une grille ou des axes gradués, qui surchargeraient inutilement le graphique. Précisons que les données de l’étude sont téléchargeables pour qui voudrait les consulter en détail ou, comme moi, faire ses propres graphiques.
L’aide à la lecture sous le graphique – dont on devrait même pouvoir se passer – vient surtout expliciter les notations « D1-D10 ». Pour soulager le lecteur et lui éviter de scanner le diagramme, elle se rapporte au premier chiffre, au premier symbole visuel rencontré dans le sens de la lecture.
Certains sigles sont explicités : CMU-C, ACS. D’autres libellés sont un peu abrégés pour une meilleure homogénéité et un bandeau d’en-tête réduit à 3 lignes seulement. Tous les textes s’affichent à l’horizontale, le lecteur n’a pas à torturer ses cervicales pour comprendre un axe.
La date des données est plus clairement exposée, de fait elle est un peu ancienne. Depuis, CMU-C et ACS ont été fusionnées dans une nouvelle mesure : la « complémentaire santé solidaire » (2019).
Le titre enfin, l’élément le plus important de cette visualisation, expose le message clé. Sur deux lignes, il présente une coupure « logique » en fin de première ligne (règle de lisibilité trop méconnue elle aussi). La nature de l’indicateur présenté apparait en sous-titre, c’est à la fois nécessaire et suffisant.
Ce n'est pas au lecteur de faire l'effort de déchiffrer, c'est à vous de faire lisible et mémorable
On le voit, cette nouvelle représentation ne prend pas plus de place que l’original. Elle expose autant de données et surtout elle révèle bien davantage, avec plus d’efficacité. Davantage qu’un tableau croisé mis en couleurs, tel quel, dans un « grapheur », elle traduit la démarche analytique du rédacteur-concepteur. Chaque petit ciselage compte et contribue à l’évidence de l’ensemble : confort, équilibre, simplicité, mémorabilité.
Ce n’est pas au lecteur de faire l’effort de déchiffrer vos graphiques, c’est à vous, auteur, statisticien, expert du sujet, pédagogue obstiné, de faire ce qu’il faut pour que le ou les messages principaux « sautent aux yeux ».
Ce travail, la « résolution du problème graphique » comme l’énonçait Bertin, apporte beaucoup de plaisir à celui qui le mène. Des outils intelligents comme DataWrapper – conçus par des sémiologues avertis – le rendent accessible à tout un chacun en offrant de tester en confiance différentes variantes. Ne vous en privez pas, et surtout n’en privez pas vos lecteurs !
« La plus grande qualité d'une image,
c'est quand elle nous amène à remarquer
ce que l'on ne s'attendait pas à voir. »John Tukey, Exploratory Data Analysis, 1977
Pour aller plus loin
Voici quelques ressources :
[1] Stacked bars are the worst, Robert Kosara, 2016
[2] Psychologie de la forme, Wikipedia
[3] What to consider when creating stacked column charts, Lisa Charlotte Muth, 2018
PS : Il faudrait conduire un autre genre d’étude pour comprendre l’étrange fascination qu’exerce le diagramme en barres empilées sur le statisticien. J’ai quelques hypothèses en tête. Ce visuel consacre le geste statistique canonique, croiser deux critères. Il permet de « mettre à disposition » dans un petit espace un volume significatif de données. Docile à la mise en couleurs, il ravit le concepteur tout comme le maquettiste. Ne cédant pas à la facilité d’un message trop trivial, il rappelle – discrètement – que l’accès à la connaissance se mérite !
Merci Éric pour ces conseils toujours pertinents et cette prise de recul sur la lisibilité des données.
Merci Régis, je suis ravi que ces digressions sémiologiques vous aient intéressé !
Merci beaucoup Éric pour cette belle leçon ! Je suis ravi de vous avoir offert un aussi bon exemple de ce qu’il ne faut pas faire, et surtout d’avoir découvert grâce à cela l’existence de la sémiologie graphique, dont je n’oublierai pas de sitôt les préceptes.
Merci Mathieu pour ce commentaire qui m’impressionne, j’espère avoir su trouver le ton juste pour commenter cet extrait graphique, d’une étude de fond par ailleurs justement saluée pour sa qualité technique et son originalité !
Bonjour Éric,
Merci beaucoup pour ces différents billets de blog sur la sémiologie, on apprend beaucoup. Je compte justement transformer un graphique en pile dans sa version désagrégée que tu présentes. Est-ce que tu fais cela sous R ? Avec ggplot2 ? Merci par avance si jamais tu as quelques conseils voire lignes de code ou packages à recommander.
Bonjour Mathias, et merci pour ton intérêt pour la sémiologie. J’utilise en première intention Datawrapper, qui ne demande pas de changer la structure des données pour passer de barres empilées à séries de barres. Sinon, pivot_longer() dans R, UNPIVOT dans DuckDB sont tes amis ! Enfin, l’interface de RawGraphs https://app.rawgraphs.io/ permet facilement de passer en format long un tableau croisé classique.