On ne sait pas toujours à l’avance ce que l’on va trouver dans un fichier CSV, pouvoir s’en faire un aperçu, quelle que soit sa taille, est bien appréciable. C’est ce que permet EmEditor, et dans une moindre mesure, Notepad++.
Ce tweet récent (octobre 2021) illustre bien les difficultés que chacun rencontre au quotidien, s’il aime à moissonner des jeux de données de toutes origines. Il faut en lire les commentaires pour comprendre à quel point il parait difficile d’apprivoiser un tel fichier (tous les noms de domaine en .fr), qui n’a pourtant que sept petits millions de lignes ! La discussion se termine même par des noms d’oiseau, les Linuxiens se moquant de la prétention des « petits joueurs sous Windows » à se tirer d’un tel défi. Vous verrez à la fin de cet article que ce n’est pas bien compliqué.
Question technique :
— MonsieurBlu (@MonsieurBlu) October 11, 2021
J'ai récupéré un fichier CSV contenant quelques millions de lignes (l'ensemble des domaines enregistrés en .fr)
Excel ne sait pas l'ouvrir entièrement.
Quel outil saurait le faire ?
Si vous voulez tester, le fichier est disponible sur https://t.co/QNzCSb54FV pic.twitter.com/L3zoMsTfcN
EmEditor et Notepad++ : deux éditeurs de texte
avec des aptitudes spécifiques pour le format CSV
CSV, c’est par définition un format texte, et ces deux éditeurs de texte ont la particularité de prendre en compte les caractéristiques de ce format délimité : ils comprennent qu’il y a derrière une table de données structurées, avec des lignes et des colonnes. Leur force est de permettre de manipuler en douceur ces lignes (filtrages, dédoublonnage) et ces colonnes (typage, sélection, création de colonnes dérivées).
Dans un article comparatif intégrant aussi le programme iNZight, j’ai confronté de façon systématique, avec différents tableaux, les fonctionnalités de ces outils. Je vais ici exposer l’intérêt d’EmEditor, puis de Notepad++, au travers de deux explorations concrètes.

EmEditor gère un fichier CSV de 2 Go,
y compris en jointures
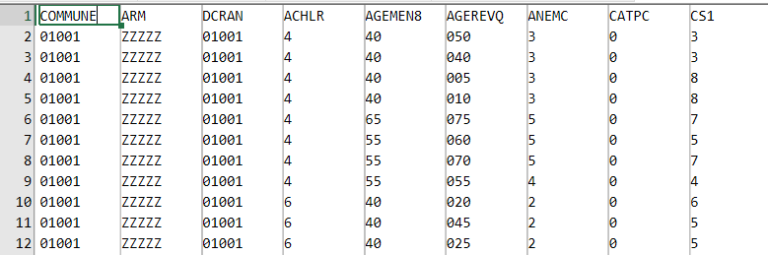
Je m’intéresse tout d’abord à la base des migrations résidentielles en France, l’une des plus grosses bases mises à disposition par l’Insee. Elle décrit les changements de résidence d’une année sur l’autre, par commune, avec de multiples caractéristiques pour les personnes considérées.
20 millions de lignes et 33 colonnes, c’est ce qu’annonce la page de téléchargement. Une fois le transfert dézippé, j’obtiens un CSV de 2 Go. Clic droit/ouvrir avec EmEditor, en moins d’une seconde je dispose d’un aperçu, et je peux faire défiler le contenu jusqu’à la fin :
Je m’inspire dans cette exploration d’un cas réel, qui m’a été présenté récemment : constituer une base d’études restreinte à une métropole, en extrayant les arrivants et les partants pour ce seul territoire. N’y étant pas parvenu avec R (mémoire insuffisante), mon interlocuteur s’en était finalement sorti en chargeant le fichier complet (le CSV de 2 Go) dans une base PotsgreSQL, puis en programmant jointure et filtres en SQL. Je ne sais combien de temps il y a passé au juste, mais je peux imaginer…
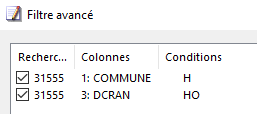
Avec EmEditor, ça prend juste quelques minutes. À titre d’échauffement, commençons par extraire les lignes concernant les personnes ayant quitté Toulouse, ou à l’inverse ayant emménagé à Toulouse. En SQL, cela s’écrirait : COMMUNE = ‘31555’ OR DCRAN = ‘31555’. Ici on construit un filtre avancé avec deux critères combinés selon la conjonction OU :
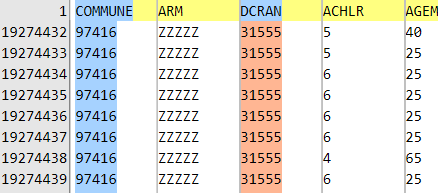
En une poignée de secondes, le filtre dégage 200 000 lignes – notez que la ligne d’en-tête reste toujours visible :
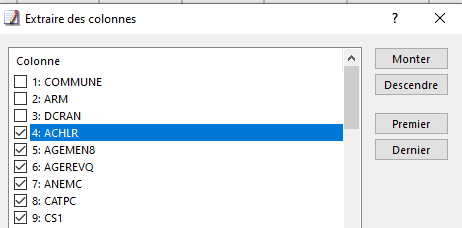
Avant d’enregistrer cet extrait, je peux choisir les seules colonnes qui m’intéressent, et même les réordonner à ma guise :
Pour étendre la démarche à la métropole de Toulouse, un EPCI, je charge une table de passage communes => EPCI, sous la forme d’un second fichier CSV, que je filtre sur le code EPCI 243100518 : il liste donc les seules communes de la métropole de Toulouse :
Je procède à une jointure entre ces deux tables, précisant quelles sont les colonnes que je veux conserver. Cette opération – la plus exigeante en ressources – requiert une petite minute :
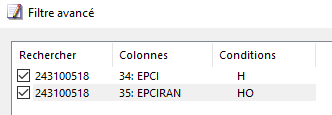
Une seconde jointure sur le même principe, à partir du code DCRAN, permettra d’injecter le code EPCIRAN de résidence antérieure. Il ne reste plus qu’à filtrer le résultat selon la condition : résidait dans la métropole de Toulouse, OU a emménagé dans la métropole de Toulouse :
J’obtiens ainsi l’extrait recherché, de 282 000 lignes. Toute cette séquence a pris moins de 5 mn.
Pour prendre un autre exemple, un data-journaliste évoquait récemment sur Twitter ses heures de galère – « crise de nerf » se plaint-il – rien que pour rendre traitable ce fichier sur la fiscalité locale. Sans être d’un poids démesuré (100 Mo), ce CSV a la particularité de compter plus de 1 000 colonnes ! Bien peu de programmes savent ouvrir un tel fichier. EmEditor le fait en un clin d’œil, et vous permet de choisir les seules colonnes qui vous intéressent.
EmEditor présente bien d’autres capacités étonnantes en matière de tables CSV : tableaux croisés dynamiques (et donc agrégation de variables numériques), transposition inverse (de format large vers format long), concaténations de colonne, dédoublonnages…
Et si vous maitrisez un peu les expressions régulières, peu de fichiers mal organisés résisteront à vos envies de nettoyage !
Je l’utilise depuis plus de 10 ans, et n’ai jamais regretté mon investissement, tant il m’a fait économiser des heures de travail.
Notepad++ est à l'aise pour requêter 7 millions de lignes
Notepad++ est un éditeur de texte très utilisé en première intention par les développeurs : il agrémente d’une coloration syntaxique le code écrit dans une multitude de langages. Avec les deux extensions CSV Lint et CSV Query, il offre des facilités de manipulation de documents CSV, il suffit de les activer dans le gestionnaire des extensions :
J’ouvre ici une base communale de naissances domiciliées, CSV Lint distingue chaque colonne par la couleur, et me permet d’accéder à la structure des variables, de la valider et l’ajuster si besoin. Ainsi, « Validate data » détecte que la première colonne des codes commune n’est pas assimilable à un nombre. Mais je peux ajuster le type de CODGEO en remplaçant Integer par Text, et revalider avec succès.
Cette fonction de validation est utile si l’on publie soi-même un fichier CSV, et que l’on veut s’assurer que sa structure est correcte. Un délimiteur manquant sera par exemple détecté, et le n° de ligne correspondant signalé.
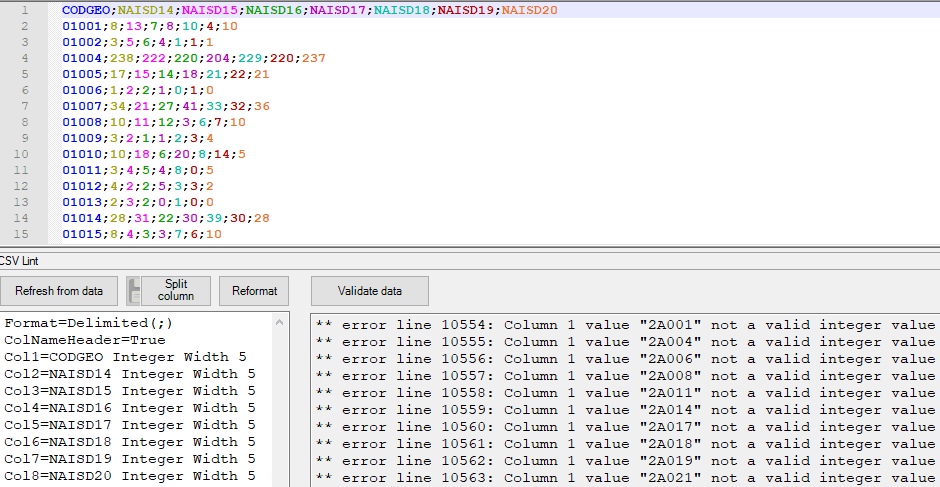
Un rapport d’analyse complet est accessible, colonne par colonne :

CSV Lint propose un peu de nettoyage (suppression de blancs superflus), et de séparer une colonne par délimiteur ou indice.
Il fournit les instructions SQL pour charger votre CSV dans une base de données :
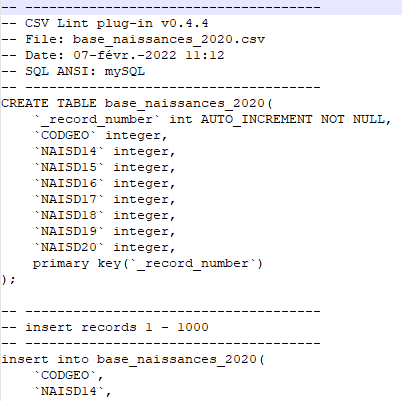
Si vous êtes familier de SQL, un second plugin, CSV Query, vous permet de requêter votre table CSV comme s’il s’agissait d’une table SQL. En fait, il charge vos données dans une base SQLite locale, de façon totalement transparente :
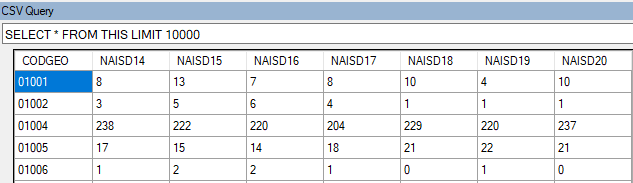
À partir de là, avec SQL, tout devient possible, ou presque : tris, filtres, agrégations, jointures multi-tables, calcul de nouvelles variables… Il ne manque que les transpositions. Le résultat se copie et/ou s’exporte en CSV.
Notepad++ n’a pas la puissance d’EmEditor, il peinera un peu plus à charger des fichiers de plusieurs centaines de Mo. Tentons toutefois d’apprivoiser le fichiers des noms de domaine en .fr mis à disposition par l’Afnic, que le tweet de MonsieurBlu cité en haut de ce billet évoquait comme franchement difficile à travailler avec ses 7 millions de lignes (il s’en est finalement sorti en le découpant en 8 morceaux).
Si ce n’est qu’une formalité instantanée pour EmEditor, Notepad++ s’en tire plutôt bien, affichant ces 500 Mo de données en 20 secondes :
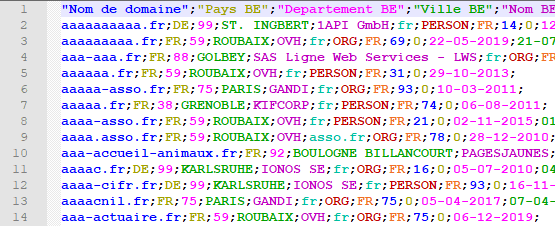
Pour chaque nom de domaine en .fr (j’ai rapidement retrouvé icem7.fr !), on accède à quelques infos sur le « bureau d’enregistrement » et sur le détenteur.
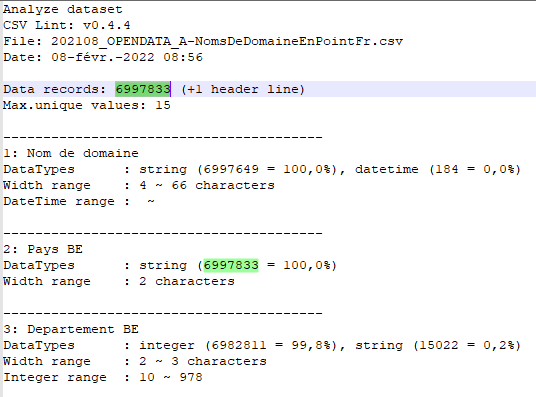
CSV Lint produit son rapport d’analyse, aide toujours précieuse pour comprendre le contenu de chaque colonne.
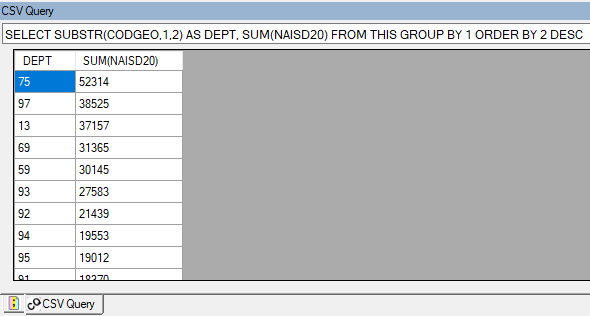
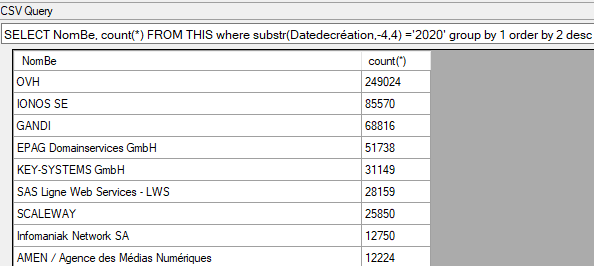
Avec CSV Query, les données sont chargées automatiquement en SQLite, en moins d’une minute. J’interroge ensuite, en SQL, cette table de sept millions de lignes à ma convenance, par exemple ici pour dégager un comptage pour l’année 2020 par bureau d’enregistrement :
Le même exercice avec EmEditor est beaucoup plus rapide et ne nécessite aucun codage d’instruction, tout se passe par menus :

En conclusion
Si vous êtes expert en bases de données, il ne vous sera pas bien difficile de charger, dans MySQL ou PostgreSQL par exemple, un fichier CSV massif, et vous l’interrogerez ensuite à votre guise en SQL. R a également progressé dans sa capacité à gérer de gros volumes. J’ai longtemps pratiqué de la sorte.
Mais il m’est vraiment agréable de pouvoir aller bien plus vite, quand je ne sais pas encore ce que je vais trouver dans un fichier potentiellement intéressant. Devoir gérer de multiples environnements et en passer par du codage introduit une friction qui, en définitive, vous ralentit et vous prive de potentielles précieuses découvertes.
Pour aller plus loin
EmEditor
Notepad++
Billets connexes dans ce blog
- Exploiter tous les fichiers CSV, petits ou (très) grands, avec quelques outils simples
- iNZight : le tapis volant néo-zélandais de la statistique
Données exemples