![]() Cet étonnant outil libre de l’Université d’Auckland répondra à nombre de vos besoins de manipulation de fichiers CSV et, bien au-delà, d’analyse statistique exploratoire – que vous soyez expert ou novice. Programme autonome, il s’installe sous Windows, sur Mac ou en environnement Linux. iNZight mobilise toute la puissance du langage R, mais de façon assistée, visuelle et progressive.
Cet étonnant outil libre de l’Université d’Auckland répondra à nombre de vos besoins de manipulation de fichiers CSV et, bien au-delà, d’analyse statistique exploratoire – que vous soyez expert ou novice. Programme autonome, il s’installe sous Windows, sur Mac ou en environnement Linux. iNZight mobilise toute la puissance du langage R, mais de façon assistée, visuelle et progressive.
Je l’ai découvert grâce à Alberto Cairo, un des grands auteurs du champ de la datavisualisation, qui le mentionne dans sa boîte à outils favoris.
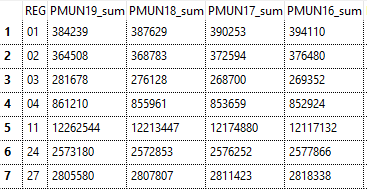
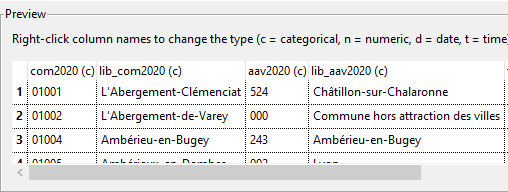
Pour un européen, le premier choc émotionnel positif se produit à l’ouverture d’un CSV ordinaire : le délimiteur ; ne pose aucun problème et les colonnes sont proprement typées par défaut, même les codes communes Insee ! Vous pouvez si besoin ajuster le type avant de confirmer le chargement.
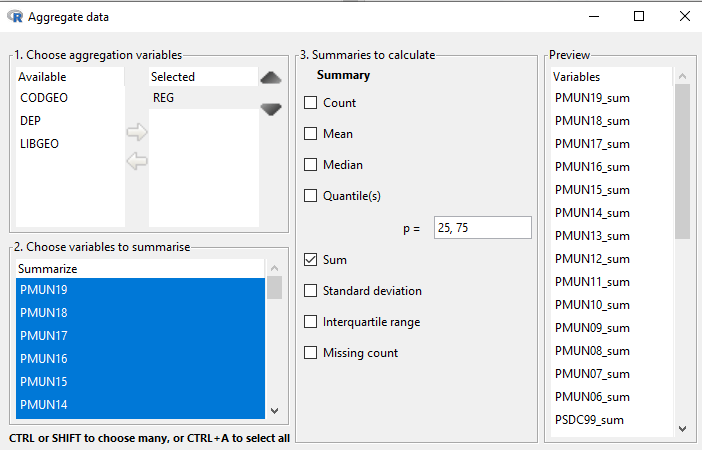
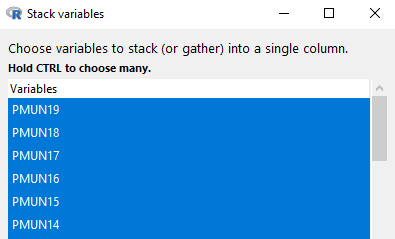
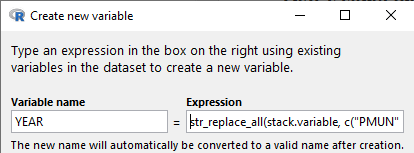
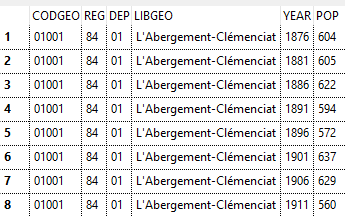
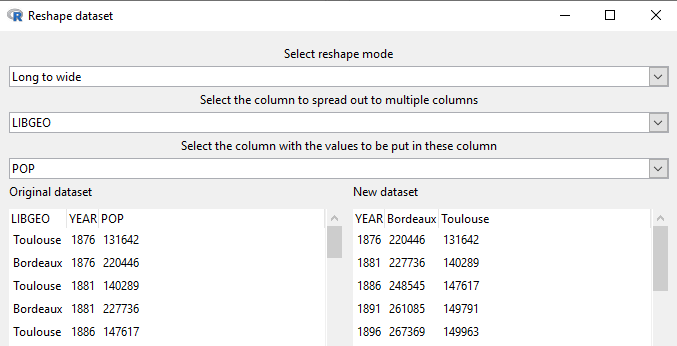
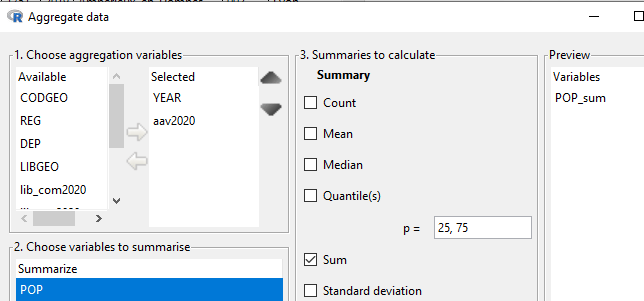
INZight fait bien mieux : il agrège, transpose dans les deux sens, gère les jointures entre fichiers différents, permet de créer de nouvelles colonnes ou de ne conserver que les lignes et colonnes dont on a besoin. Chaque nouveau traitement crée une table distincte de l’original, il est donc aisé de revenir en arrière et choisir une nouvelle trajectoire.
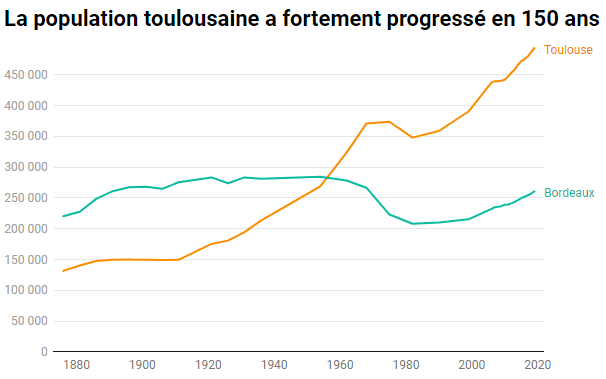
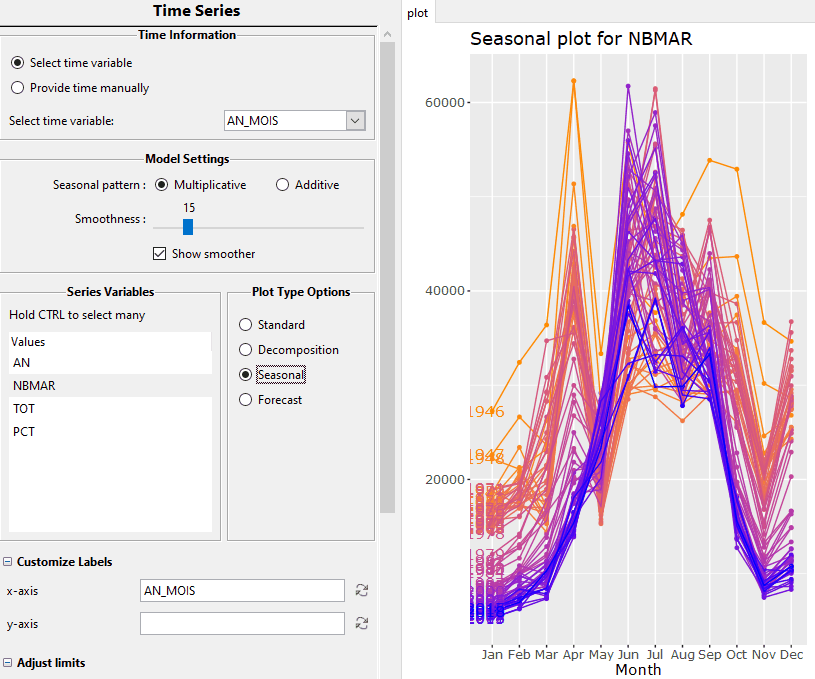
Last but not least, iNZight facilite l’analyse exploratoire de vos données par toute une gamme de graphiques automatiquement construits en fonction du type de vos colonnes. Il va même jusqu’à désaisonnaliser des séries temporelles, construire une analyse factorielle visuelle en quelques clics, produire des cartes thématiques et réaliser des tests statistiques.
Ses concepteurs, soutenus par le ministère de l’Éducation néo-zélandais, en ont promu l’usage dans les lycées du pays, comme outil de familiarisation avec les concepts de la statistique.